
前言
这是这个项目的 Github 地址 DAWN0ER/WordCount
这个项目发起前我还没有实习,基本就是头铁一顿乱写,功能可以实现就行,然后就写的十分不规范和诡异,比如RPC 没有防腐层,Dao 层直接和 Mapper 交互,而没有中间一层包装器,redis 和 kafka 也是直接交互,做的十分粗糙,自己有点看不下去了,就打算重构整个项目,然后就发生悲剧了。
技术选型
架构:SSM(SpringBoot,Spring MVC,Mybatis)
RPC框架:Dubbo
注册中心:Zookeeper (不用 Nacos 了,感觉有点大)
定时任务:Quartz
消息队列:Kafka(可以考虑用 Kraft 模式,不过都有 Zookeeper 了就直接用 Zookeeper)
数据库:MySQL
架构设计
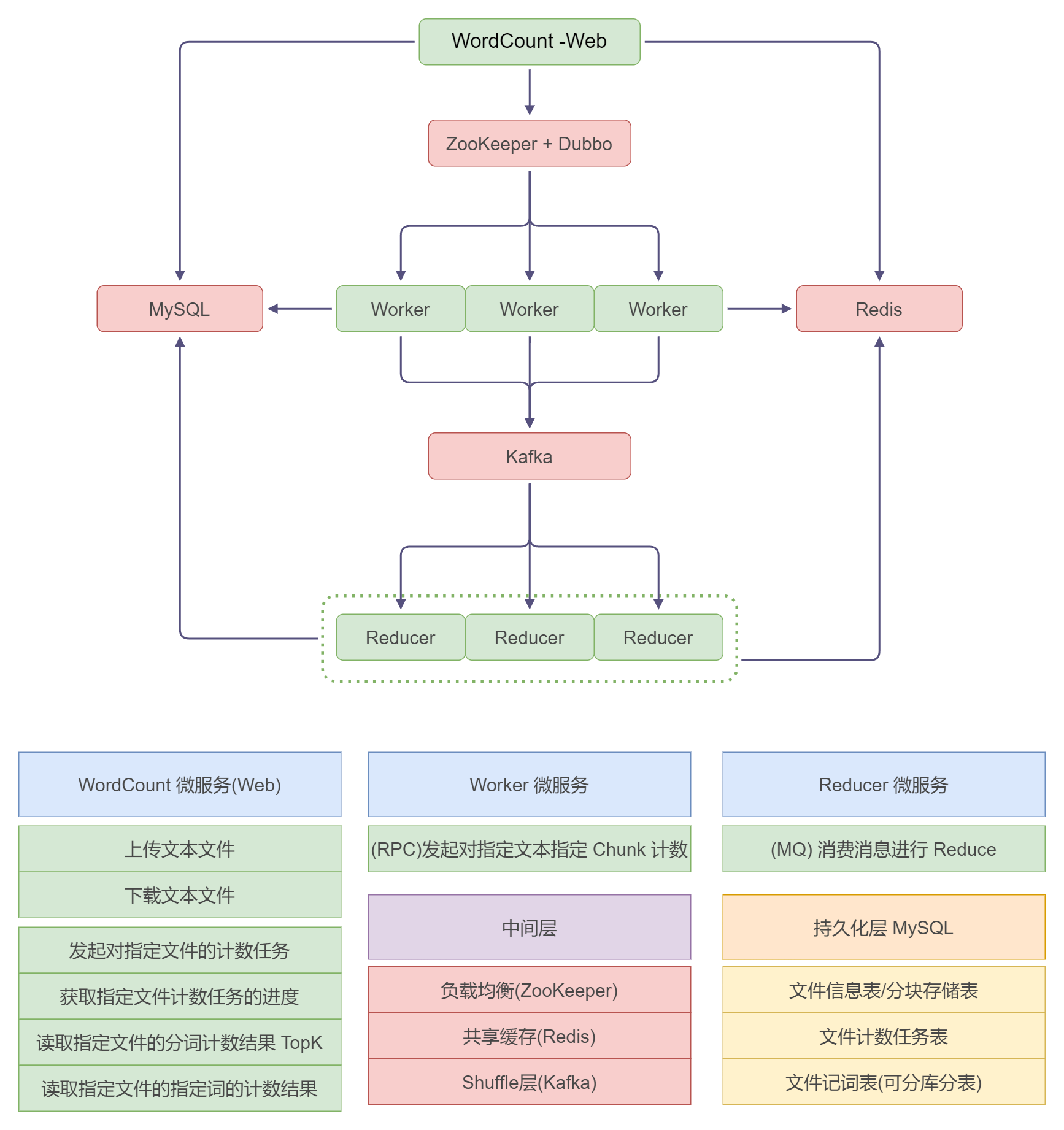
WordCount 服务层
- 文件存储:
- 文件上传,分区块储存到 MySQL,区块大小要求:一个 Worker 能处理的大小
- TODO: 引入多数据源(业务数据源和 Quartz 数据源)
- 文件下载,分区块存储的能够一次性全部下载完成
- TODO: 如果文件真的很大的话,需要考虑用其他的 S3 存储方案了,暂时这样
- 文件上传,分区块储存到 MySQL,区块大小要求:一个 Worker 能处理的大小
- 分词计数
- 发起对指定文件的计数任务
- 添加一个延时守护线程,用来多次轮询一个任务的完成情况并同步
- 需要在 Redis 中队 BitMap 设置超时时间
- 获取指定文件前K个热点词
- TODO 暂时使用 ORDER BY 后续可以性能优化
- 获取指定文件指定词(可多个)的计数
- 发起对指定文件的计数任务
Worker 集群
- 依靠 Dubbo 自己的负载均衡策略(默认随机均衡)
- 通过 RPC 调用发起分词计数任务
- 作为 Kafka 消息的生产者
- 采用 Kafka 的 Partition 特性实现 Shuffle,指定 Partition 发送对应消息
- 不同 Hash 的负载均衡
Reducer 集群
- Kafka 消费者集群对词进行整合,同步进度
实现方案
Restful URL
/api/v2/file
| 功能 | 方法 | 路径 | RequestBody |
|---|---|---|---|
| 上传文件 | POST | /upload | @RequestParam("file") MultipartFile file |
| 下载文件 | GET | /download/{fileUid} | - |
/api/v2/word-count
| 功能 | 方法 | 路径 | RequestBody |
|---|---|---|---|
| 开启计数 | POST | /count | @RequestBody int fileUid |
| 获取进度 | GET | /progress/{taskId} | - |
| topK热点词 | GET | /file/{fileUid}/top/{K} | - |
| 获取指定words的计数 | GET | /file/{fileUid}/words | @RequestBody List<String> words |
RPC接口
public interface WorkerService {
/**
* 同步计数
* @param chunkCountTaskDto 入参
* @return 返回 map 到的 partition 数量
*/
Integer countWordsOfChunk(ChunkCountTaskDto chunkCountTaskDto);
/**
* 异步完成计数
* @param chunkCountTaskDto 入参
*/
void countWordOfChunkAsync(ChunkCountTaskDto chunkCountTaskDto);
消息队列
topic: word_count
数据库
CREATE TABLE IF NOT EXISTS file_info
(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
file_uid INT(10) UNSIGNED NOT NULL COMMENT '文件标识id',
file_name VARCHAR(128) NOT NULL COMMENT '文件名',
chunk_num INT(10) NOT NULL COMMENT '分区数量',
status TINYINT NOT NULL DEFAULT 0 COMMENT '文件状态(1-初始化, 2-已存储, 3-损坏, 4-任务中, 5-任务完成)',
created_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updated_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY pk (id),
UNIQUE KEY file_uid_key (file_uid)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
AUTO_INCREMENT = 1 COMMENT '文件基础信息表';
CREATE TABLE IF NOT EXISTS file_chunks
(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
file_uid INT(10) UNSIGNED NOT NULL COMMENT '文件标识id',
chunk_id INT(10) NOT NULL COMMENT '分区id',
context TEXT NOT NULL COMMENT '分区主要内容',
PRIMARY KEY id_key (id),
UNIQUE KEY file_uid_chunk_id (file_uid, chunk_id)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
AUTO_INCREMENT = 1 COMMENT '文件存储表';
CREATE TABLE IF NOT EXISTS word_count
(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
file_uid INT(10) UNSIGNED NOT NULL COMMENT '文件标识id',
word CHAR(20) NOT NULL COMMENT '分词',
cnt INT NOT NULL COMMENT '计数',
PRIMARY KEY id (id),
UNIQUE KEY file_word (file_uid, word)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
AUTO_INCREMENT = 1 COMMENT '分词计数表';
CREATE TABLE IF NOT EXISTS word_count_task
(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
task_id BIGINT(20) UNSIGNED NOT NULL COMMENT '任务标识id',
file_uid INT(10) UNSIGNED NOT NULL COMMENT '文件标识id',
status INT NOT NULL DEFAULT 0 COMMENT '1-待完成,2-已完成,3-异常',
created_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updated_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY pk (id),
UNIQUE KEY task_id_key (task_id),
KEY file_uid_key (file_uid)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
AUTO_INCREMENT = 1 COMMENT '分词统计任务表';
可能存在的坑点
- Dubbo 测试的 Mock 问题
- Quartz 的多数据源问题
- RPC 服务的循环依赖问题
- Redis 粗颗粒锁更新 BitMap
- 重构就是噩梦
重构后的感悟
谁爱重构谁去重构去吧,虽然每次看到自己以前写的这些 Shit 真的很难受,但重写所有功能让人感觉更加难绷,过去垃圾代码的回旋镖终究是回到了自己身上。
关于程序员的东西也思考了很多,最后还是觉得自己应该是一个以业务场景为驱动的研发工程师,技术终究是用不完也学不完的,但技术是为了业务服务的,做业务的程序员死磕技术上的各种效能和比较没有意义,只有放在场景里面才有效,去学架构设计和业务场景的开发吧,同时也不能忘记各种新的知识的学习。