
通过单机周期任务的实现,聊一聊 DelayQueue 和 ScheduledThreadPoolExecutor
本期聊一聊单机服务的定时任务有哪些方案,也学习一下 JDK 里的一些定时执行相关的工具是如何设计的。这里的定时任务指的是心跳/采样信号这类的定时速率执行的周期任务,不是用 Cron 表达式定时定点调度的哪种任务。
面对这一类单机周期任务的场景,JDK 其实提供了两个工具来实现周期/延时执行任务,一个是 DelayQueue,另一个是 ScheduledThreadPoolExecutor,本期我们简单分析一下两者的源码,聊一聊这两个之间千丝万缕的联系。
核心概念
JDK 的延迟队列是 public class DelayQueue<E extends Delayed> extends AbstractQueue<E> implements BlockingQueue<E>,继承了基本的队列抽象模板,同时实现了 BlockingQueue 接口,接下来我们聊聊这两个抽象类的源码。
DelayQueue 继承自 AbstractQueue<E> 并实现了 BlockingQueue<E> 接口,同时要求元素实现 Delayed 接口。下面是这三个核心接口的关键方法:
| 接口 | 关键方法 | 作用 |
|---|---|---|
Queue | offer() / poll() / peek() | 非阻塞式入队/出队/查看 |
BlockingQueue | put() / take() | 阻塞式入队/出队 |
Delayed | getDelay(TimeUnit) | 返回剩余延迟时间 |
// Delayed 接口 - 要求实现 getDelay 和 compareTo
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit unit);
}
DelayQueue 核心数据结构
DelayQueue 的底层存储数据结构是 PriorityQueue<E extends Delayed>,由于 Delayed 类原生实现了 Comparable 接口,所以可以直接复用优先级队列的实现。Java 的优先级队列底层采用数组式完全二叉树实现最小堆,这个实现我们后续也会在 ScheduledThreadPoolExecutor 里看到。
DelayQueue 内有两个重要的成员对象,是控制延迟消费的关键。第一个是final ReentrantLock lock,以及 ReentrantLock 衍生的条件变量 final Condition available = lock.newCondition();,Delay Queue 底层便是通过 ReentrantLock + Condition 来实现阻塞等待的。
take() 方法实现
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null)
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
return q.poll();
first = null; // don't retain ref while waiting
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}
加锁竞争
在方法的最外层,首先会尝试加锁,加锁的原因比较简单:并发控制(因为对底层 PriorityQueue 的读写是非线程安全的)+ Condition 的线程状态控制。
加锁的方法是 lockInterruptibly,允许锁等待的时候线程被中断,这个方法的选择来自于 BlockingQueue 接口的要求E take() throws InterruptedException,要求线程中的每个环节都是可线程中断的。
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
......
} finally {
......
lock.unlock();
}
}
这里有一个没啥用的知识点分享,
final ReentrantLock lock = this.lock;,是 Doug Lea 大佬写代码的一种风格,可以在这些邮件交流里找到一些相关信息。在当时,在成员变量使用前声明为方法局部变量可以减少生成的字节码量,并在当时(2004年)对部分场景下的性能优化较好,是一种“将代码写得接近机器码的极端优化手段”。但是后续 Java 编译器和 JIT 发展过程中,这部分优化已经下沉到编译器和 JVM 里了,在 Java 代码里这样写代码是一种不建议的行为,在
ReetrantLock的官方示例里也是直接使用成员变量。这算是一个历史遗留的痕迹,并不是什么当前值的我们学习的技术细节,这也告诉我们:在学习一些优秀项目的同时,也需要用结合发展的轨迹去学习,像这些已是陈年往事的设计该忽略忽略。
循环阻塞等待消费
加锁后的内一层是一个无限循环,唯一的跳出入口是 return q.poll();,也就是不断阻塞等待循环,直到获取到待消费的元素,这部分流程图简化一下如下:
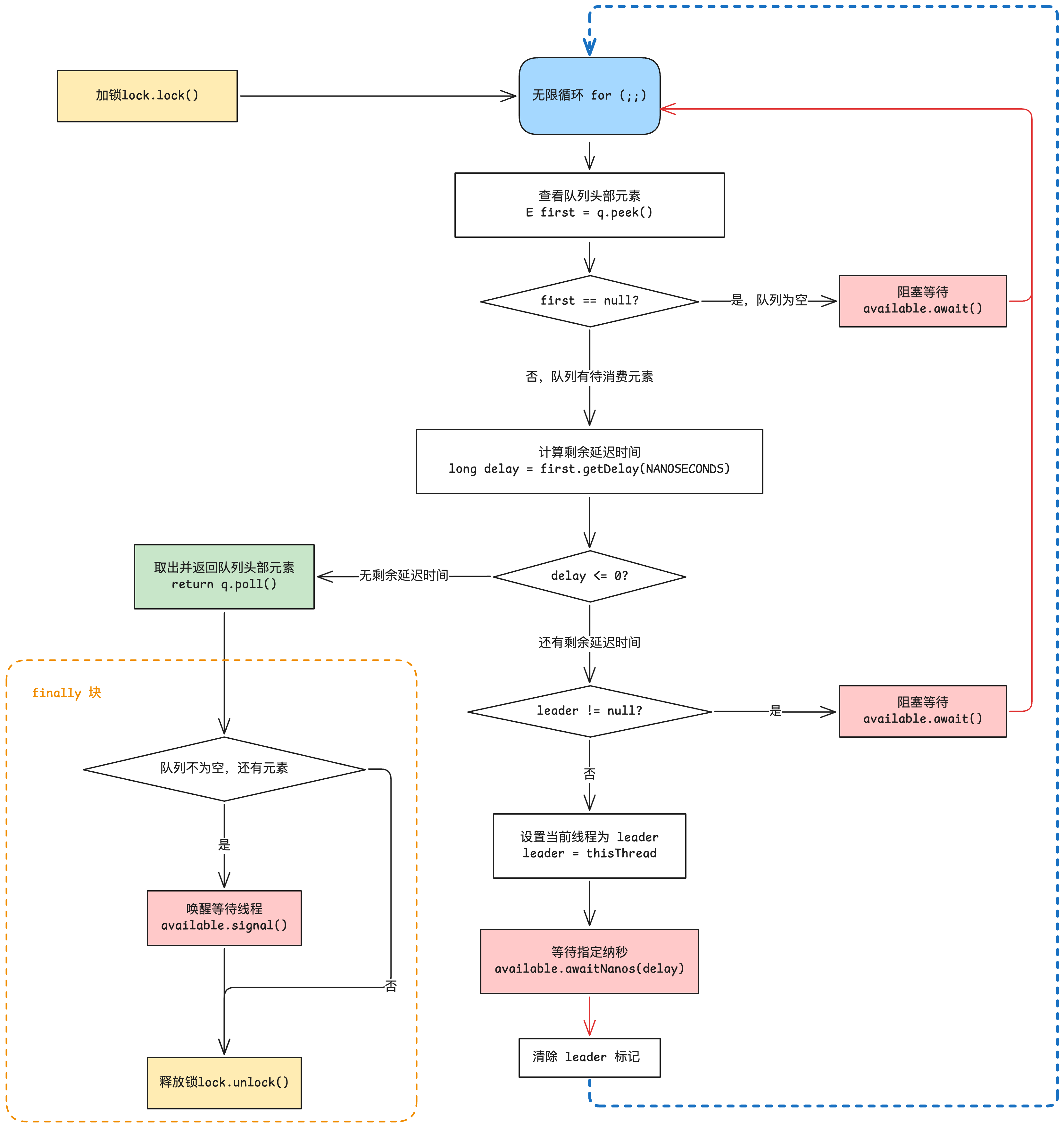
流程说明:简化来说,当线程抢占到锁时,如果当前队列没有待消费元素,或者头部元素没达到延迟时间,就会通过 Condition 触发线程等待Condition.await(),释放锁,然后等待条件唤醒时(比如新元素入队时唤醒)重新抢占锁,重新进入循环尝试消费元素,如果有可以消费的元素,就返回该元素,同时跳出这个无限循环。
惊群效应优化
这里面有一个优化的细节,由于是延时队列,相较于普通的阻塞队列,会多一次阻塞等待。第一次阻塞等待是当队列为空时,阻塞等待元素入队后消费;第二次阻塞等待是当队头元素还有剩余延时时间的时候,会阻塞等待对应的时间后再取出消费。
Condition 的等待唤醒是本质是让当前线程阻重新获取锁,所以在一般情况下,一个线程调用 take 方法,会经历下列流程:
调用 take 方法 --> 竞争获取锁 --> 队列为空,阻塞等待队列中加入元素 --> (加入元素)线程唤醒,竞争获取锁 --> 队列不为空,但是队头元素还未到延时时间,阻塞等待对应时间 --> (等待时间结束)线程唤醒,竞争获取锁 --> 消费已到达延时时间的队头元素
如果每个线程在第二次阻塞,也就是等待头部元素到达延时时间时,均采用 awaitNanos(delay) 阻塞等待指定的时间,则会导致惊群效应,大量的线程同时唤醒去重新获取锁,触发严重的锁竞争问题。
因此,延迟队列针对做了优化,当线程获取到锁,且队列不为空时,先将 leader 标记为当前线程,表示头部元素已经被当前线程“预定”了,只有当前线程可以通过 awaitNanos(delay) 阻塞等待指定的时间,其他的线程只能继续await等待队列的下一个元素,这样就不会发生惊群效应。而当 leader 线程被唤醒且重新获取到锁时,leader 标记才会被清除,然后重新走循环流程,获取头部元素。
如果 leader 线程被中断,也会在 finally 块中清除 leader 标记,同时异常向外传播,在外层的 finally 块中调用available.signal();唤醒一个其他的线程来重走循环,避免程序卡死。
offer() 方法实现
在解析完 take 方法之后,offer 方法的解析就十分简单了:
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); // 两个原因:
// 1. 底层的 PriorityQueue 不是线程安全的,加锁;
// 2. 如果当前队列是空队列,且已有线程在阻塞等待消费,需要调用 Condition.signal() 方法,前置需要线程加锁。
try {
q.offer(e);
if (q.peek() == e) { // 如果有阻塞读的线程唤醒,这个和下面的 take() 方法联动解读
leader = null; // leader 是为了避免惊群效应,这里删除 leader 标记,避免唤醒的不是 leader 线程导致卡住
available.signal(); // 唤醒一个阻塞等待的线程
}
return true;
} finally {
lock.unlock();
}
}
ScheduledThreadPoolExecutor 源码分析
ScheduledThreadPoolExecutor 实现了 ScheduledExecutorService 接口,这个接口是 ExecutorService 的一个子接口,定义如下,主要新增了四个与延迟执行和周期执行相关的方法。
public interface ScheduledExecutorService extends ExecutorService {
// 延迟执行一次任务
ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);
// 延迟执行一次任务,返回结果
<V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);
// 固定延迟周期性执行(任务结束后开始计算下次延迟)
ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
// 固定间隔周期性执行(任务开始后开始计算下次延迟)
ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
}
ScheduledThreadPoolExecutor 本质是 Java 线程池,里面的方法涉及到不少线程池的状态流转以及生命周期的相关流程,这些线程池相关的代码比较复杂,和本期主题无关,所以这一部分我们略过,主要看一下延时执行的实现逻辑。线程池里的每一个线程都是一个 Worker,在生命周期内会不断从 wokerQueue 中获取任务 (java.util.concurrent.ThreadPoolExecutor#getTask),工作队列 wokerQueue 本质是一个实现了 BlockingQueue<Runnable> 接口的队列,在 getTask 方法中,主要调用BlockingQueue#take方法,所以,我们主要关注一下 ScheduledThreadPoolExecutor 的任务队列是如何实现的。
我们在使用 ScheduledThreadPoolExecutor 的时候,会发现这个特殊的线程池的构造方法只允许调控三个参数
public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory, RejectedExecutionHandler handler)
显而易见,可配置参数比普通的线程池少了一些,首先是没有最大线程数和 keepAlive 参数,因为 ScheduledThreadPoolExecutor 只有核心线程,没有动态最大线程。
第二个缺失的参数就是 workerQueue,因为 ScheduledThreadPoolExecutor 的工作队列是自己实现的,是一个实现了 BlockingQueue 的内部类:static class DelayedWorkQueue extends AbstractQueue<Runnable> implements BlockingQueue<Runnable>。如果我们将这个内部的 take 方法实现源码和 DelayedQueue 的对比,会发现两者实现高度相似(见下图):

所以具体的延迟获取任务的实现细节这里就不展开了,和上文的 DelayedQueue 一致。我们聊一聊 DelayedWorkQueue 这个内部类的优先队列是如何实现的,在源码中,优先队列的底层存储是一个数组:
private RunnableScheduledFuture<?>[] queue = new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
为什么是一个数组呢?这其实是一个最小堆的主流实现方案:完全二叉树实现最小堆,具体的实现方法我们按下不表,如果大家有兴趣看一下优先级队列 PriorityQueue 的源码,就会发现,优先级队列也是这么实现的:
/**
* Priority queue represented as a balanced binary heap: the two
* children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The
* priority queue is ordered by comparator, or by the elements'
* natural ordering, if comparator is null: For each node n in the
* heap and each descendant d of n, n <= d. The element with the
* lowest value is in queue[0], assuming the queue is nonempty.
*/
transient Object[] queue; // non-private to simplify nested class access
简而言之,ScheduledThreadPoolExecutor 的任务定时执行,和 DelayedQueue 的定时执行的实现方式是完全一致的,大家完全可以用相互替换来实现延迟任务。
DelayedQueue queue = new DelayedQueue();
queue.offer(new DelayedTask(1_000_000)); //延迟 1 mills
new Thread(()->{
queue.take().run();
}).start();
// 约等于
ScheduledExecutorService pool = ScheduledThreadPoolExecutor(1);
pool.schedule(new Task(), 1_000_000, TimeUnits.NANOSECONDS);
性能差异分析:任务取消
但既然这两个的底层实现完全相同,为什么 ScheduledThreadPoolExecutor 的底层存储不直接使用 DelayedQueue,而是要重复实现一个几乎一模一样的 DelayedQueue,还重复实现了一遍 PriorityQueue,这算不算是在重复造轮子?
先说结论:不算。原因可以在 ScheduledThreadPoolExecutor 的内部类 ScheduledThreadPoolExecutor.ScheduledFutureTask 的 cancel 方法里找到答案。
大家在使用 ScheduledExecutorService 的时候应该注意到,提交延时任务/周期任务的方法都会返回一个 ScheduledFuture,这个 Future 除了用于包装返回值,还有其他功能,比如监控异常,取消任务。
当我们提交一个延时/周期任务,后续又打算取消这个任务的时候,就可以调用 ScheduledFuture 的 cancel 方法,来取消当前任务的执行或后续任务的执行。这个方法实际会调用 ScheduledFutureTask 这个内部类的 cancel 方法,而这个内部类,内部会维护这个这样一个成员变量:
/**
* Index into delay queue, to support faster cancellation.
*/
int heapIndex;
这个索引会直接映射到 DelayedWorkQueue 内部的RunnableScheduledFuture<?>[] queue数组,用于快速删除任务。
在 JUC 中,所有的设计都需要为极致的并发性能服务,如果只是新增任务和获取任务,内部类 DelayedWorkQueue 和 DelayedQueue 性能几乎没有区别,因为底层的实现基本一致,只是多了几层包装调用。但在取消任务(删除任务)上,两者的区别就非常大了,DelayedQueue 的底层调用的是 PriorityQueue 的 remove 方法,对于最小堆的完全二叉树,查找的时间复杂度是 O(n)。
private int indexOf(Object o) {
if (o != null) {
for (int i = 0; i < size; i++)
if (o.equals(queue[i]))
return i;
}
return -1;
}
但对于 DelayedWorkQueue 这个内部类,由于每个任务元素都维护了自己在堆数组的索引位置,所以查找的时间复杂度为O(1),相较 PriorityQueue 有质的提升。
/**
* Finds index of given object, or -1 if absent.
*/
private int indexOf(Object x) {
if (x != null) {
if (x instanceof ScheduledFutureTask) {
int i = ((ScheduledFutureTask) x).heapIndex;
// Sanity check; x could conceivably be a
// ScheduledFutureTask from some other pool.
if (i >= 0 && i < size && queue[i] == x)
return i;
} else {
for (int i = 0; i < size; i++)
if (x.equals(queue[i]))
return i;
}
}
return -1;
}
这样的“重复造轮子”,本质是为了更好的性能优化做的重构设计,这也是 Doug Lea 在设计 JUC 时贯穿始终的一类代码风格,高性能的设计意味着我们需要更多地从机器码的角度去考虑编写代码,为了高性能删除任务这一个功能去重构一个定制化的 DelayedQueue,这样的取舍十分值得。
实战:实现单机周期任务
那现在需要一个线程实现周期发送心跳信号,至少有两个实现方案:
方案一:DelayQueue 实现
DelayedQueue queue = new DelayedQueue();
HeartBeatTask task = new HeartBeatTask(System.nanoTime() + 1_000_000_000L); // 首次延迟 1s
queue.offer()
Thread heartBeatThread = new Thread(()->{
try{
for(;;){
HeartBeatTask task = queue.take();
// 固定间隔周期性执行(任务开始后开始计算下次延迟)
long startTime = task.getStartNanoTime();
queue.put(new HeartBeatTask(startTime + 1_000_000_000L));
task.run();
}
} catch(InterruptedException e){
...
}
});
heartBeatThread.setName("HeartBeatThread")
heartBeatThread.setDeamon(true);
heartBeatThread.start();
方案二:ScheduledThreadPoolExecutor 实现
ScheduledExecutorService scheduledThreadPool = new ScheduledThreadPoolExecutor(1);
// 固定间隔周期性执行(任务开始后开始计算下次延迟)
scheduledThreadPool.scheduleWithFixedDelay(new HeartBeatTask(), 1, 1, TimeUnit.SECONDS);
方案对比
| 特性 | DelayQueue | ScheduledThreadPoolExecutor |
|---|---|---|
| 学习成本 | 较高,需自行管理线程 | 较低,API 简洁 |
| 线程管理 | 手动创建维护 | 自动管理 |
| 任务取消 | O(n) 查找 | O(1) 快速定位 |
| 推荐场景 | 自定义调度逻辑 | 生产环境通用 |
选型建议
- 推荐 ScheduledThreadPoolExecutor:API 简洁、功能完善、性能更优
- DelayQueue 适用于:学习底层原理、自定义调度策略等特殊场景
显然,周期任务线程池实现起来方便又快捷,这也是目前主流推荐的周期任务实现方案。不过我们也要清楚,两者的底层实现逻辑并没有本质上的区别,希望这篇文章对你以后排查问题有帮助。